For a long time, statisticians argued the answer was basically ‘no.’
With the 2024 European Football Championship on the horizon, I decided I’d do a series of posts on the quirks of football analysis, and what they can reveal about broader statistics and science, based on my research for The Perfect Bet.
It all began with an exam question. In the 1990s, statistics students at Sheffield University were tasked to predict which team would win a theoretical football match. It was something of a throwaway scenario, an illustrative problem to evaluate students’ knowledge of processes that involve uncertainty.
Except it turned out to be significantly more than that. The concept contained within that question – and its resolution – would end up challenging entrenched notions about the role of randomness in the beautiful game. It would also lay the groundwork for an entirely novel industry of sports analysis in the UK.
Football forecasts would never be the same again.
From seasons to single matches
During the 1970s and 1980s, it appeared there was an inherent boundary to what football analysis could achieve. Although expert predictions about performance over an entire season tended to align with actual league positions, forecasting individual matches was significantly harder.
Unlike the high-scoring outcomes in basketball, or the structured pitcher-vs-batter duels in baseball, football matches can pivot on a single moment. Victory – or defeat – may depend on whether the ball hits the post, or deflects unpredictably. One 1971 paper even asserted that ‘luck dominates the game.’
If we aim to predict an event – like the outcome of a football match – it helps to have three essentials. First, we require data on results in past matches. Second, we require data on the factors that might influence the result of a match. And finally, we require a mechanism to transform these factors into a practical prediction.
Which is where the Sheffield exam question came in. Rather than attempt to predict the outcome outright, as prior studies had done, it instead asked students to estimate the number of goals each team would score. The various possible numbers of goals – and their respective probabilities – could then be converted into a prediction about the overall outcome.
It was quite a rudimentary method, but statistician Mark Dixon saw something promising in it. Along with fellow researcher Stuart Coles, he would expand the ideas and ultimately apply them to real football league data. The resulting method – now known as the ‘Dixon-Coles model’ – would be published in 1997.
So, how did it function?
Measuring quality
Suppose we want to determine the number of goals a team might score. One of the simplest methods to achieve this is to define the typical rate at which they score goals on average – perhaps based on some kind of ‘quality metric’ – then calculate the probability they will score 0, 1, 2, 3, etc., goals over the duration of a game, based on this assumed rate.
Statistics enthusiasts will recognize that, if we assume goals occur independently of each other over time, we can calculate these probabilities using a Poisson distribution. For instance, if a team on average scores 2 goals per game, then the Poisson distribution – which encapsulates the randomness at which these goals might occur over time – would predict the following probabilities of scoring different numbers of goals:
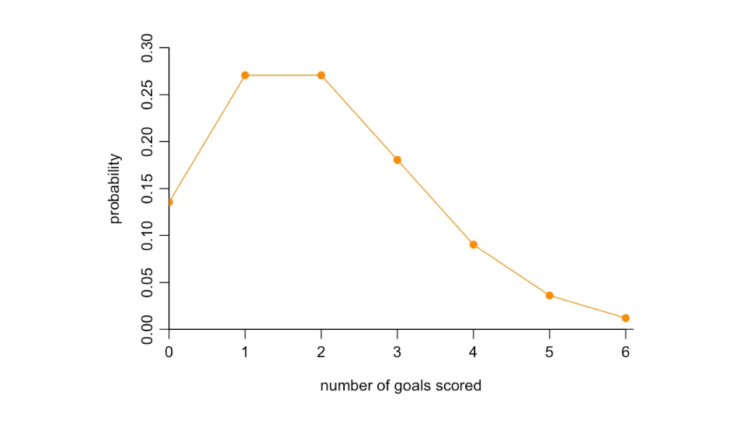
But there’s a drawback. Here we are summarizing team quality in a single metric, whereas in reality, several factors might affect how one team performs against another. This is why one analysis of the 2008 Euros found that the ranking of two teams was a very poor indicator of who will win a specific match. We’re just not capturing enough information about performance if we try and condense quality into a single metric for each team.
The basic Dixon-Coles model ended up incorporating two quality factors for each team (attacking strength and defence) as well as a factor to account for home advantage. Suppose one team H, playing at home, competes with team A, playing away. The expected number of goals per match scored by team H against team A in the model was therefore calculated as:
Team H attacking strength × Team A defensive weakness × Home advantage
Likewise, the expected number of goals scored by team A would be:
Team A attacking strength × Team H defensive weakness
But Dixon and Coles soon noticed this basic approach had some defects. First, the above assumes scores are independent; if team H are likely to score 1 goal, it doesn’t impact the probability that team A will score 1 goal. They found this assumption was reasonable for higher-scoring games but didn’t capture the frequency of low-scoring games (0-0, 1-0, etc.) in the data.
Another defect is that attacking strength and defensive weakness won’t necessarily remain the same over time. Some teams may improve or deteriorate over the season. So as well as refining the model to make low scores more likely than a simple Poisson process would predict, they allowed team quality to fluctuate over time, so recent performances mattered more than those in the distant past.
Beating the bookmaker
With these refinements, the Dixon-Coles model was sufficiently accurate at predicting matches to outperform the results implied by bookmakers’ odds. In other words, it paved the way for a lucrative betting strategy.
But what about tournaments like the Euros? In football leagues, teams play each other repeatedly, a bit like a research group repeating experiments under a variety of conditions. In contrast, tournaments leave us with much less data to analyze. Teams can play opponents they’ve never faced before, fielding players who may never have competed together.
This data gap is illustrated by the variability in betting odds we can observe between bookmakers during tournaments. One 2008 analysis found that ‘arbitrage opportunities’ – where match odds differ so much you can profit by backing both teams with two different bookmakers – were particularly prevalent during the Euros.
Researchers – and bettors – now have vastly more data available than in that 1997 Dixon-Coles paper, but the fundamental divide between predicting a league and a tournament persists. And yet, ultimately, this is what makes tournaments like the Euros so compelling. Assumptions about quality collapse more easily. Expectations about scorelines are more likely to be overturned. And, like exasperated students grappling with unpredictability amid the time pressure of an exam, we watch as pre-match predictions wrestle against the chaos of surprise upsets.